
キーワードを入れても判例がなかなか見つからず、困ったことありませんか。
その背景には、判例検索エンジンと一般的な Googleなど、一般的な検索エンジンとの仕組みの違いがあります。
本記事では、検索エンジンを構成する三つの要素を起点に、なぜ専門的な判例検索システムが必要とされるのかをわかりやすく解説し、判例調査を効率化するための考え方を紹介します。
目次
Toggle一、Google検索と判例検索エンジンの違い
(一)Web検索エンジンの基本概念
多くの弁護士にとって、情報検索をする際に、まず頭に浮かんできたのは GoogleやYahoo!でしょう。
Google のようなWeb検索エンジンはインターネット上に存在する膨大な「ウェブページ」を対象に、ユーザーが入力したキーワードとの関連性が高いページを素早く見つけ出し、結果を提示する検索エンジンとして設計されています。
しかし、Googleが評価しているのは、あくまで「ページの内容」や「被リンク数」、「更新頻度」などであり、そのページに掲載されているコンテンツ自体がリーガールリサーチには役立てるかという点までは判断していません。
一方、弁護士や法務が本当に求めているのは、単なる情報ではなく、実務で使える判例或いは法的情報です。
この根本的な目的の違いが、一般的な検索エンジンと判例検索エンジンの差を生み出しています。
(二)判例検索はなぜGoogleだけに頼れないのか
そのため、判例調査としては、Googleだけでは不十分であり、専門的な判例検索システムが必要になります。
法律検索の場面では、まったく同じキーワードを用いたとしても、事案によって法的効果や判断の方向性が大きく異なることがあります。
たとえば、「不当利得」といった同一の法律概念であっても、裁判所や事件類型、前提となる事実関係が異なれば、検索結果として得られる判例の内容は大きく変わります。
さらに、法律分野では専門用語、条文用語、実務慣行に基づく表現が多用されます。
一般的なキーワード検索では、こうした文脈の違いを正確に捉えることができず、結果として重要な判例を見落としたり、関係の薄い情報に時間を費やしたりすることになりがちです。
(三)検索エンジンとしての役割の違い
判例検索エンジンの最大の特徴は、検索対象が「ページ」ではなく「判例そのもの」である点です。
一つ一つの判例は、裁判所、裁判日、争点、主文、事実及び理由といった複数の要素から構成されています。
検索エンジンがこれらを理解できなければ、弁護士にとって有用な検索結果を提供することはできません。
そのため、判例検索エンジンは、法律特有の構造と文脈を理解する前提として設計されています。

二、判例検索エンジンの基本構造
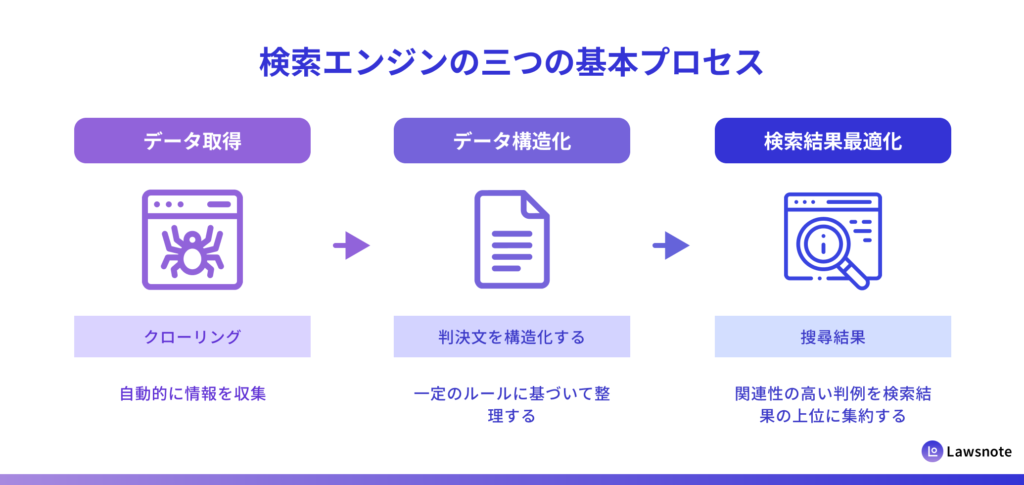
検索エンジンの三つの基本プロセス
検索エンジンは、いずれも共通して三つの工程によって機能しています。
- データ取得
- データ構造化
- 検索結果最適化
詳細な仕組みは後ほど解説しますので、ここではまず検索エンジンの基本となる考え方を押さえておきましょう。
まず、「クローラー」と呼ばれるプログラムが Web 上のリンクを自動的に巡回し、情報を取得します(クローリング)。次に、取得した情報は検索エンジンのデータベースに登録され、一定のフォーマットに従ってデータを整理・処理されます(インデックス/構造化処理)。そして、アルゴリズムに基づいてデータの関連性を評価し、検索意図に最も合致する結果を上位に表示します。
これは Google検索 であっても、専門的な判例検索エンジンであっても基本的な流れは同じです。
ただし、判例検索エンジンでは、対象となるのが法律文書であるため、どのようにデータを取得し、どのように構造化し、どの基準で順位付けを行うかが、検索精度を大きく左右します。
優れた判例検索エンジンを構築するための鍵は、これら三つの工程を法律データの特性に合わせて適切に設計することにあります。
(一)データ取得
1. クローリングとは何か:判例検索における役割
クローリングとは、Web上のページを巡回し、自動的に情報を収集する仕組みです。
判例検索においては、裁判所が公開している判例情報を、継続的かつ体系的に取得するためにクローリングが用いられます。
人手による収集では、更新漏れや取得範囲の偏りが生じやすいため、判例データベースの構築にはクローリングが不可欠です。
クローリングのメリット:
- 長期的かつ自動的にデータを更新できる
- 大量の判例を体系的に収集できる
- 人為的な取得漏れや重複ダウンロードを防止できる
2. 判例データはどこから取得されるのか
判例データの収集を始めるにあたって、まず理解しておくべき重要な前提があります。判決書は裁判所が作成する公的文書であり、原則として著作権法の保護対象外とされています。ただし、判決書を編集・整理・加工した編集著作物や、付加価値を加えたコンテンツについては、別途著作権が成立する可能性がある点には注意が必要です。
判例データの主な取得元は、裁判所が公式に公開している判例情報や、適法な許諾を得た判例資料です。ただし、「公開されている」ことと「自由に利用できる」ことは同義ではなく、利用方法や商用利用の可否については、情報源ごとの利用規約や法的制約を確認する必要があります。
現在、判例検索エンジンにおけるデータソースは、大きく 公式公開情報 と 非公式に整理されたプラットフォーム(有料の判例データベースなど) の二つに分類できます。公式公開情報は、判決書全文を原文のまま取得できる点で高い信頼性を有しますが、検索や分析に必要な構造化が十分に施されていない場合が多いという課題があります。一方、非公式の判例データベースでは、判例があらかじめ整理・構造化されて提供されることが多いものの、その編集内容が著作権の保護対象となるか、また商用利用にどのような制限があるかを事前に確認することが不可欠です。
さらに重要なのは、取得した判例データは、そのままでは検索エンジンで活用できないという点です。判例は、裁判所や審級、作成年、事件類型によって形式や記載方法が統一されておらず、情報の粒度にもばらつきがあります。そのため、クローリングによって収集されたデータは、多くの場合「素材」に過ぎず、実務で利用できる検索データとするためには、一定のルールに基づいた加工や整理が必要になります。
こうした理由から、判例検索エンジンでは、クローリングの次の工程として、判決書を検索可能な形に整えるデータの構造化処理が不可欠となるのです。
(二)データ構造化
1. データの構造化とは何か:判決文を構造化する
構造化データとは、判例に含まれる情報を一定のルールに基づいて整理し、検索エンジンが理解・処理できる形に変換したものを指します。
具体的には、一つの判例を以下のように区別することが可能です:
- 裁判所名
- 裁判日
- 事件名
- 主文
- 請求
- 争点
一見すると、このような区分は自然であり、特別な処理が不要に思えるかもしれません。人間であれば、文章を読んで「ここが事件の概要である」「この部分が裁判所の判断理由である」と直感的に理解できます。しかし、検索エンジンにとっては、判決文全体は単なる文字列の集合に過ぎず、その法的な意味や役割を自動的に把握することはできません。
そこで重要になるのが、判決文を構造化するという工程です。構造化処理を行うことで、判例は長文のテキストから、検索や分析に適した法律データへと変換されます。これにより、検索エンジンは判例を「文字情報」ではなく、「法的意味を持つ情報」として扱えるようになり、弁護士や法律実務者の検索意図により近い形で、精度の高い判例検索を実現できます。

2. 構造化データのメリット
構造化データを用いることで、検索精度は大きく向上します。
過去、全文検索のみに依存していた場合、判例調査では次のような課題が生じがちでした。
- 検索結果に無関係な判例が大量に表示される
- キーワード自体は含まれているが判例の法的争点とは一致していない
- 複数の判例を横断的に比較し、実務上の判断傾向を把握することが難しい
一方、構造化データを活用することで、検索エンジンは「この記載は主文である」「こちらは裁判理由に該当する」といった文書内の役割を理解できるようになります。
その結果、重要な判例や特定の争点に関連する裁判例を効率的に抽出することが可能となり、リーガルリサーチの精度と実用性は大幅に向上します。こうした構造化データの活用こそが、判例検索システムにおける中核的な要素と言えるでしょう。
(三)キーワード検索と検索順位を決める判断基準
ユーザーにとって、検索の目的は「できるだけ多くの結果を見ること」ではなく、「最も関連性が高く、実務で役立つ情報を迅速に見つけること」にあります。そのため、検索エンジンにおける検索クエリの設計や順位付けのロジックは、検索体験の質を大きく左右します。
1. 検索キーワード(クリエ)と検索意図との関連性
現代の検索エンジンにおいて重要視されているのは、単なるキーワードの一致ではなく、ユーザーが入力した検索クエリに込められた「検索意図」を理解することです。
キーワードの同義語処理や関連概念の認識を通じて、検索エンジンは表記が完全に一致しているかどうかではなく、異なる表現が同一または近接した法的意味を指しているかを判断します。
この点は、判例検索において特に重要です。たとえば、「不法行為」と「不法行為責任」、「注意義務違反」と「過失」、「相当因果関係」と「因果関係」といったように、表現は異なっていても、実務上は同一の法的問題を指しているケースが少なくありません。また、法改正に伴い、新旧法の名称や略称が混在することも、判例検索を難しくする要因の一つです。
さらに、構造化データと組み合わせることで、検索エンジンは検索対象を特定の段落や項目に限定することが可能になります。
Lawsnote Search では、検索構文を用いて、特定の構造化フィールドに対する検索を行うことができます。たとえば、main: を使用することで主文のみを対象に検索したり、「裁判長:」といった指定により特定の裁判長に関連する判例を抽出したりすることが可能です。
このような構造化データを活用した検索方法によって、法律実務者は大量の無関係な検索結果に埋もれることなく、本当に必要な判例へと迅速にたどり着くことができます。

2. 検索順位を決める判断基準
検索キーワードに基づく適切なクエリ設計ができたとしても、検索結果が「使いやすい」ものになるかどうかは、最終的には検索エンジン独自の『検索アルゴリズム』によって決定されます。
検索アルゴリズムとは、データベースに登録された膨大な情報の中から、ユーザーの検索キーワードに最も関連性が高く、かつ高品質なコンテンツを判断し、検索順位(ランキング)を決める際に使うルールや計算方法のことです。
従来の検索エンジンでは、公開日時による時系列順や、タイトルにキーワードが含まれているかどうかといった単純な基準で順位付けが行われることが一般的でした。しかし、データ量が増えるにつれて、このような方法では検索結果がユーザーのニーズに十分に応えできなくなります。
これに対し、専門の判例検索エンジンでは、関連度に基づく順位付けが重視されています。単なるキーワードの一致度だけでなく、判例の内容が検索クエリに含まれる法律概念とどの程度関係しているか、実務上どの程度重要性を持つかといった要素を総合的に評価し、検索意図に最も合っている判例を優先的に表示します。
このような順位付けによって、本当に関連性の高い判例が検索結果の上位に集約され、日時や表面的な文字情報に左右されることなく、弁護士がより短い時間で必要な判例を見つけるようになるのです。

三、判例検索ツール選定のポイント:網羅性と精度のバランス
現在、市場にはさまざまな判例検索システムが存在していますが、どのサービスを選ぶべきかを判断するには、いくつかの重要な観点があります。
まず、法律実務者にとって最も重視すべきなのは、検索結果の網羅性です。特定の条件に合致する判例が漏れなく検索結果に表示されるか、また法律上の同義語や表記の違いも含めて適切に検索できるかどうかは、判例検索システムの基礎的な性能を判断する重要な指標となります。
次に重要なのが、判例検索の精度と効率性です。法律実務において、時間は非常に貴重な資源であり、必要な判例をどれだけ迅速に手にいれるかは、検索システムの価値を大きく左右します。たとえ同じキーワード検索を行ったとしても、検索結果の順位付けの方法や、構造化データへの対応状況によって、得られる結果や作業効率には大きな差が生じます。優れた判例検索システムは、検索精度の高さだけでなく、判例調査に要する時間そのものを短縮し、法律実務者の業務効率を大幅に向上させる点にこそ、その真価があると言えるでしょう。
まとめ
Google検索は日常的に使いやすい便利なツールですが、判例検索という専門的な場面では、どうしても限界があります。判例検索エンジンは、クローリング、構造化データ、検索結果の最適化といった仕組みを通じて、単なる情報ではなく実務で使える法的情報を提供するために設計されています。
判例検索エンジンの本当の価値は、技術そのものにあるのではなく、法律実務の思考や利用シーンにどれだけ寄り添っているかにあります。検索エンジンが法律特有の言語や構造、実務上のニーズを理解できてこそ、弁護士や法律実務者は、検索作業に時間を費やすのではなく、分析や判断といった本来注力すべき業務に集中できるようになります。
リーガルテックの進展により、判例検索システムの重要性は今後さらに高まっていくでしょう。だからこそ、自身の実務に適した検索ツールの仕組みを理解し、適切に選択することが、これからの法律実務において大きな差を生む要素となります。

郭 栄彦 Barry Kuo
台湾を代表するリーガルテック企業「Lawsnote」の創業者。台湾弁護士・弁理士としての実務経験を経て2016年に同社を設立し、AIを活用したリーガルテック製品の開発・普及を主導。現在はLawsnote Japanの代表として、日本の法律実務の効率化と高度化を支援しています。